Use Dataproc (Spark) and Hail on Verily Workbench
Categories:
Purpose: This document provides detailed instructions for creating and working with a Dataproc cluster in Verily Workbench.
Introduction
Dataproc is a fully managed and highly scalable service for running Apache Hadoop, Apache Spark, Apache Flink, Presto, and many other tools and frameworks. The Verily Workbench Dataproc app also supports one-click Hail installation. Hail is an open-source library for scalable data exploration and analysis, with a particular emphasis on genomics.
This document gives an overview of how to create and use Dataproc clusters, optionally with Hail, in Workbench.
Starting up a Dataproc cluster from the Workbench web UI
Navigate to the Apps tab in your workspace, click on + New app instance, then select the JupyterLab Spark cluster option.
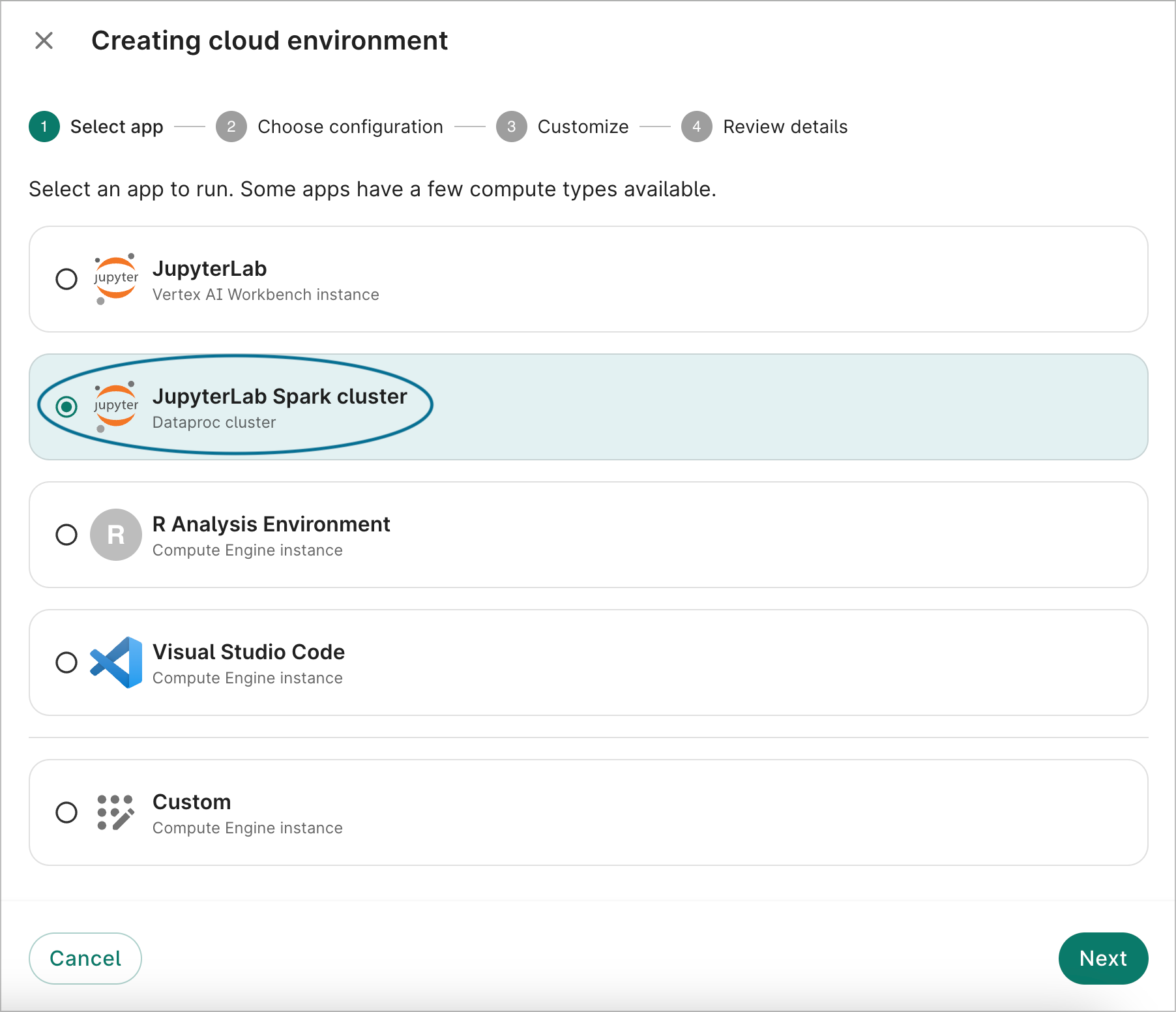
Next, choose an app configuration. You should see a default configuration, as well as any other configurations you previously created. Click Next.
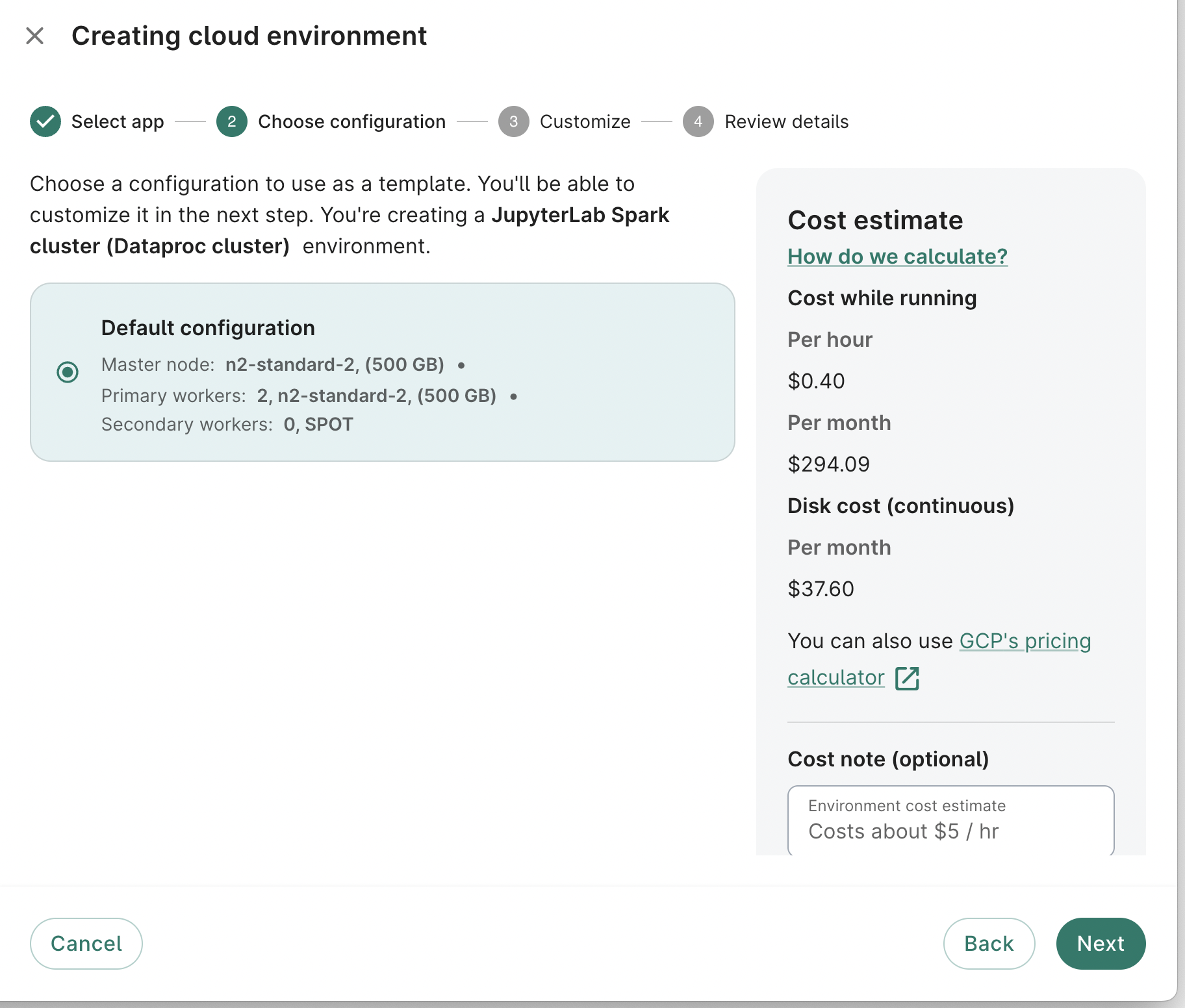
On the next screen, you can customize various aspects of your cluster:
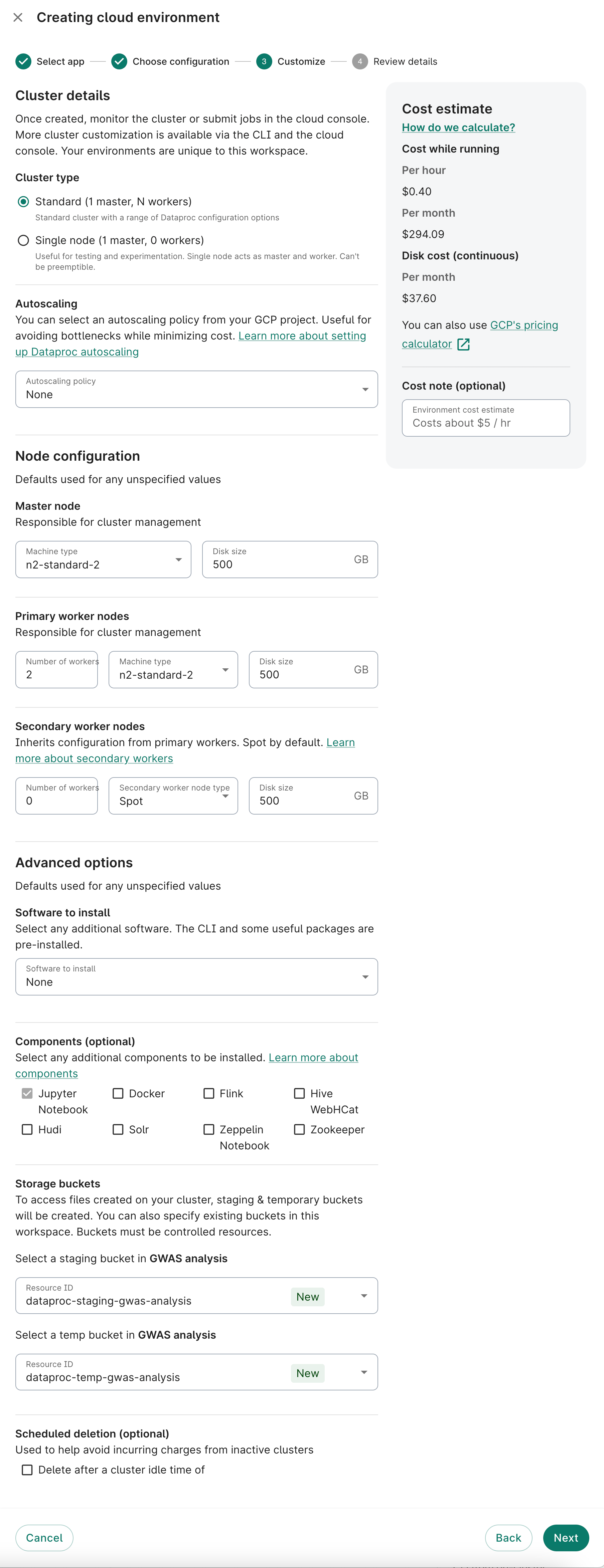
Selected parts of this form are highlighted in more detail below. After you've configured your new cluster, click Next.
Finally, you can review your app details and enter an ID, name, and description (optional) for your app. You can also optionally add a cost estimate:
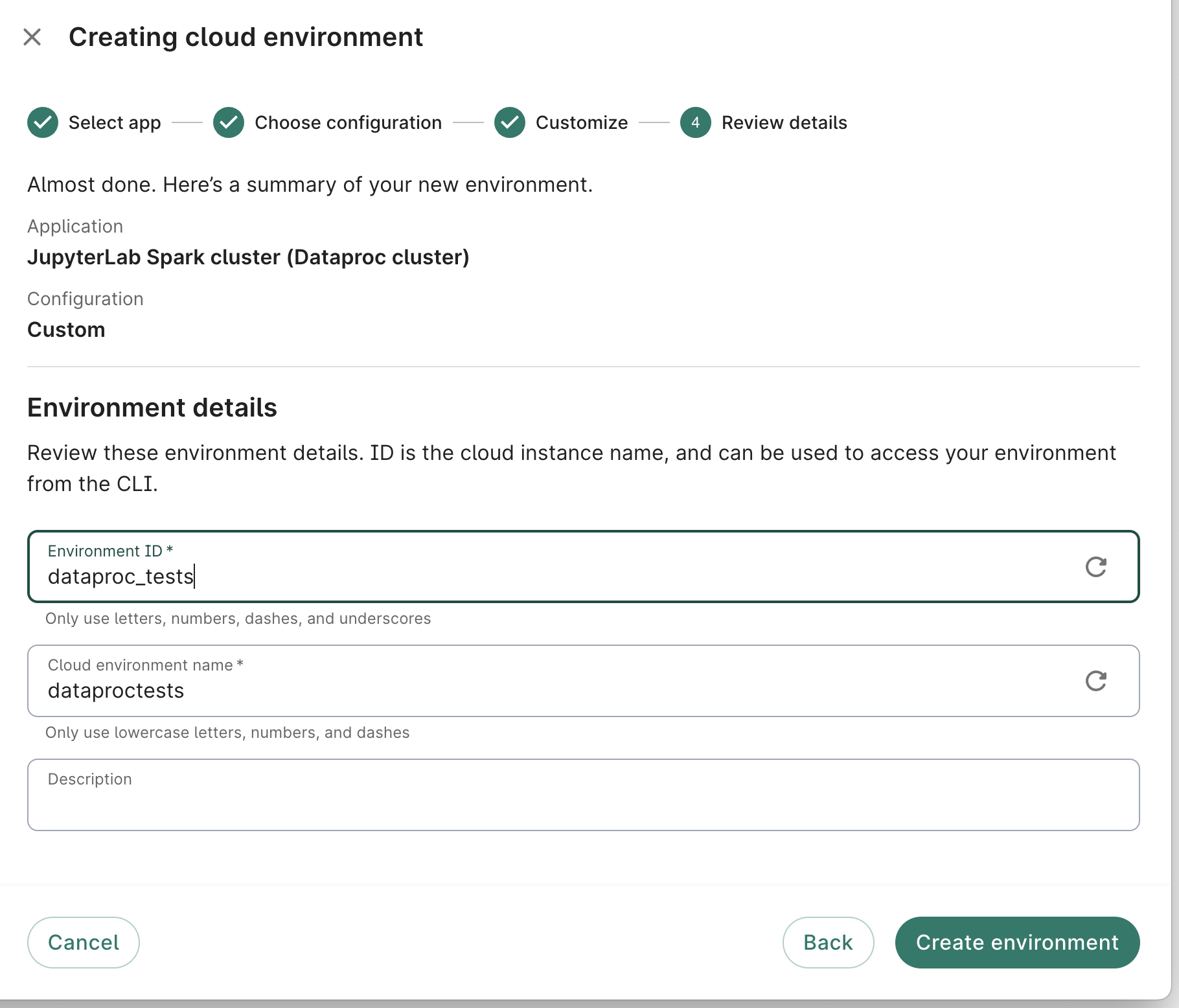
Click Create app.
Note
Cluster creation may take ~10 minutes.Autoscaling policies
The cluster creation form allows you to specify an autoscaling policy. The autoscaling policy must be created before you create the cluster.
You can read more about setting up autoscaling policies here. Once you’ve created one or more policies, the Autoscaling policy dropdown in the cluster creation dialog will be auto-populated with those policies, and you can select the one you want.
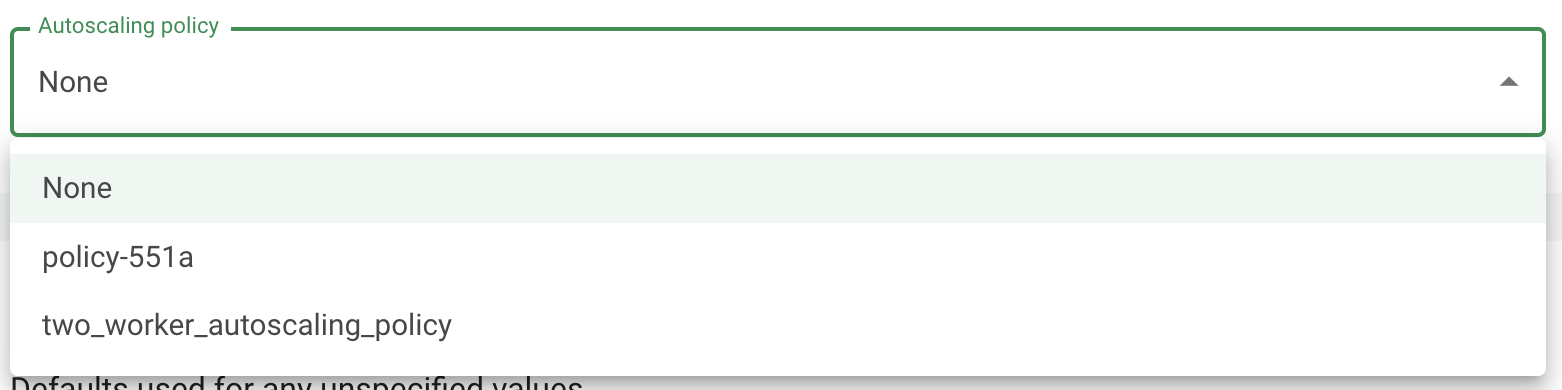
The autoscaling policies are common to the workspace’s underlying project. So, other users with
access to the workspace will be able to view the policies, and users with Writer or Owner
workspace privileges will be able to modify them. You can create policies via the Cloud console UI,
or via the gcloud SDK from the command line.
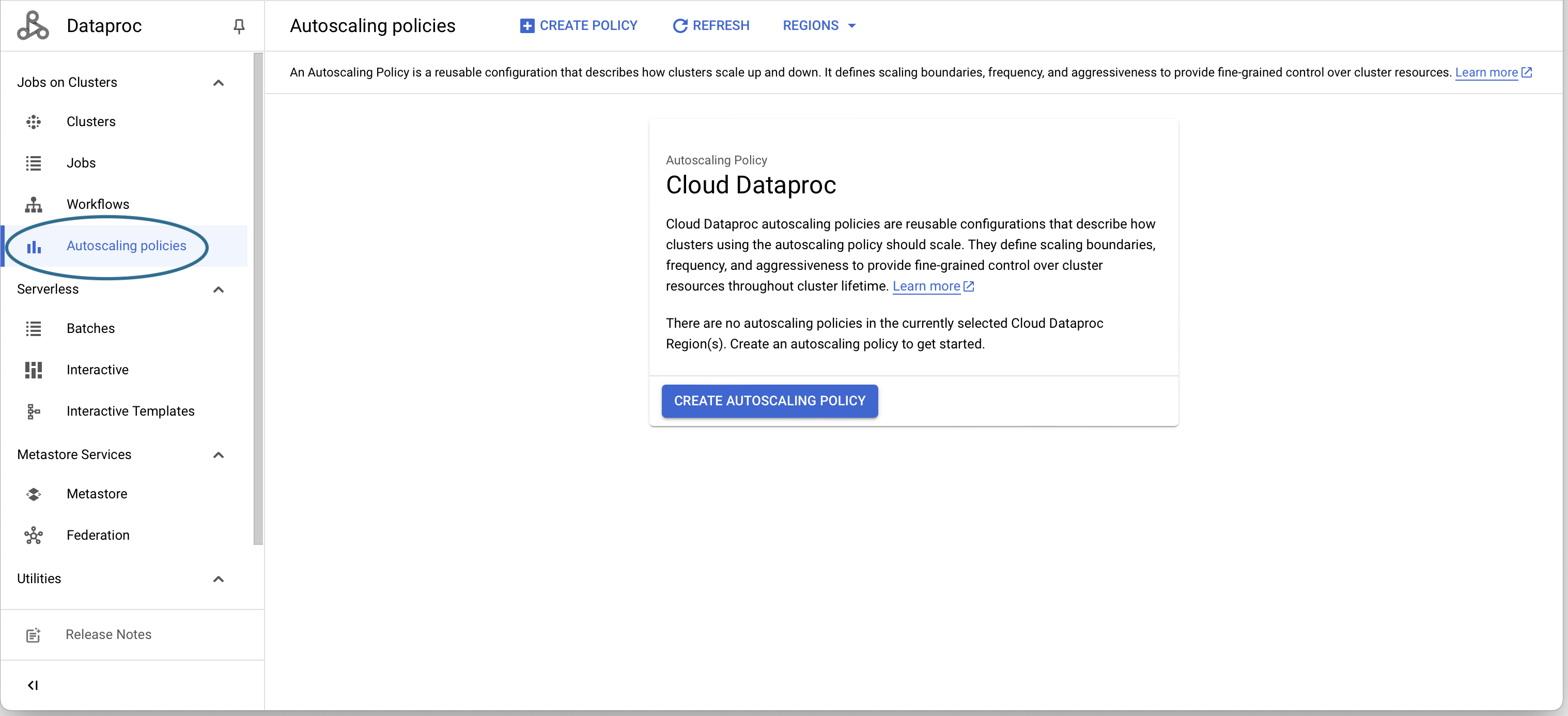
Creating an autoscaling policy via the Cloud console
Visit https://console.cloud.google.com/dataproc/autoscalingPolicies:
Creating an autoscaling policy via the gcloud SDK
Create a yaml config file (below is an example). See the Dataproc
documentation for
more details.
workerConfig:
# Best practice: keep min and max values identical for primary workers
# https://cloud.google.com/dataproc/docs/concepts/configuring-clusters/autoscaling#avoid_scaling_primary_workers
minInstances: 2
maxInstances: 2
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
Import a yaml autoscaling config to your project via gcloud. You can run this command from a
workspace notebook app, or from your local machine.
(Locally, you may need to set the
--project flag as well, if gcloud is not configured for the correct project.)
gcloud dataproc autoscaling-policies import <autoscaling_policy_name> \
--source=<your_autoscaling_policy>.yaml \
--region=us-central1
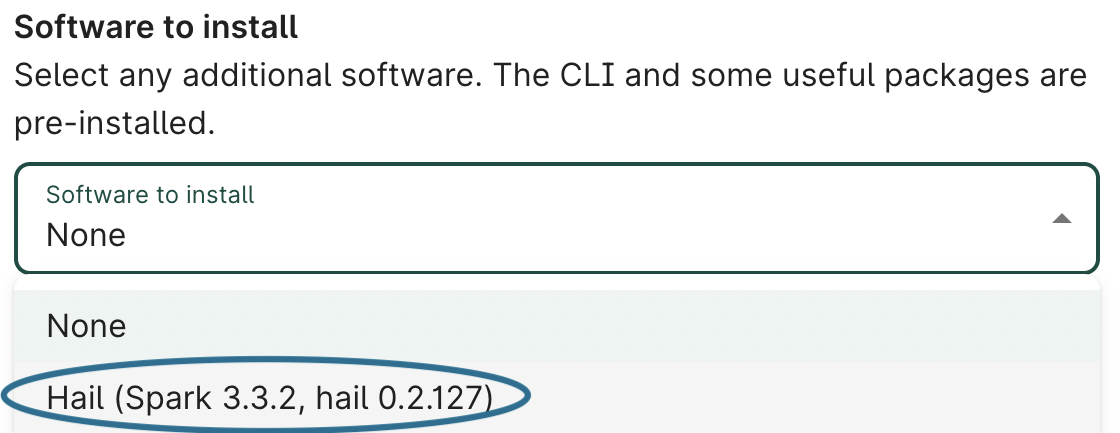
Installing Hail
To install Hail on the cluster, select it from the Software to install dropdown in the cluster creation dialog.
Note
In future, it will also be possible to provide your owninitialization-actions script(s) as well, to support other custom installations.
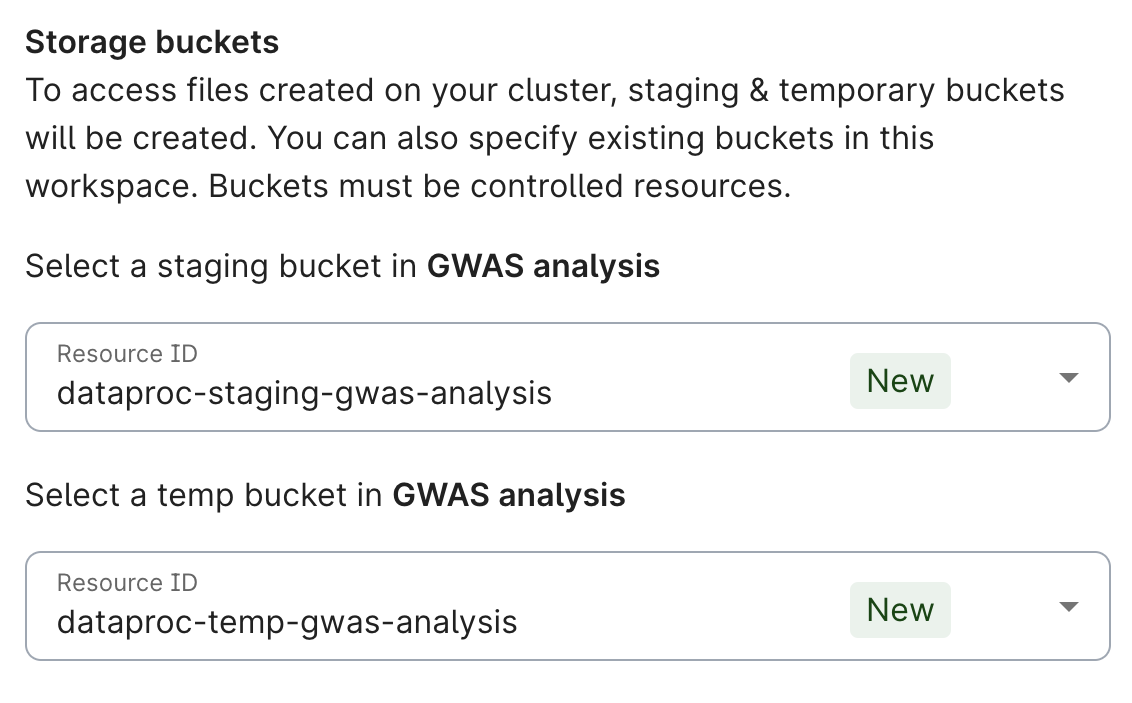
Dataproc Cloud Storage buckets
The first time a Dataproc cluster is created in a workspace, two controlled resource Google Cloud Storage buckets are automatically created: a staging bucket, and a ‘temp’ bucket.
Their resource names are: dataproc-staging-<workspace-name>, and
dataproc-temp-<workspace-name>, where <workspace name> is replaced with the name of your
workspace.
These buckets are used by default for all clusters created within that workspace, though when you create a cluster, you can instead configure the cluster to use other controlled resource buckets from the workspace. Any other buckets must pre-exist before you create the cluster, and will appear in the Storage buckets dropdowns in the cluster creation dialog.
Setting scheduled deletion
To delete your clusters after an idle period, check the following box and select the time period. By default, this box is not checked.
Currently, autostop is not supported for Dataproc clusters, though you can STOP and then later restart the clusters
(see below for more details). Note that scheduled deletion also applies to stopped clusters.

Starting up a Dataproc cluster from the Workbench CLI
You can also create a Dataproc cluster via the Workbench CLI (command-line interface).
Run wb resource create dataproc-cluster to see the options.
Many of the parameters of this command are passed through from the gcloud dataproc command. See the Dataproc
docs and reference
documentation for more details on these
parameters.
Start a cluster from the command line without Hail
If you don't want to install Hail on your Dataproc cluster, then use the following command as a starting point.
Before running the command, replace <your_cluster_name> with the name of your new cluster.
wb resource create dataproc-cluster \
--id=<your_cluster_name>
Default buckets are auto-created when you first create a cluster via the Workbench web UI.
Their resource names are: dataproc-staging-<workspace-name> and
dataproc-temp-<workspace-name>, where <workspace name> is replaced with the name of your
workspace. However, you can specify other existing buckets:
wb resource create dataproc-cluster \
--id=<your_cluster_name> \
--bucket=<staging_bucket_name> \
--temp-bucket=<temp_bucket_name>
You can also include parameters to indicate --initialization-actions scripts, set time to deletion when idle (--idle-delete-ttl, specified in seconds), set an --autoscaling-policy, indicate components to install, and much more.
For example, this command template sets up four primary and eight secondary workers, specifies an autoscaling policy, and indicates deletion after two hours of idle time:
wb resource create dataproc-cluster \
--id=<your_cluster_name> \
--bucket=<staging_bucket_name> \
--temp-bucket=<temp_bucket_name> \
--num-workers 4 --num-secondary-workers 8 \
--autoscaling-policy <your-policy_id> --idle-delete-ttl 7200s
Creating a cluster from the command line with Hail installed
If you'd like to install Hail on your Dataproc cluster, then start from this command instead:
wb resource create dataproc-cluster \
--id=<your_cluster_name> --software-framework=HAIL
As with the example in the section above, you can add additional configuration parameters (e.g., add --idle-delete-ttl 7200s to delete after two hours of idle time).
Working with a Dataproc cluster
After a cluster is up and running, you’ll see a card like this under the Apps tab:
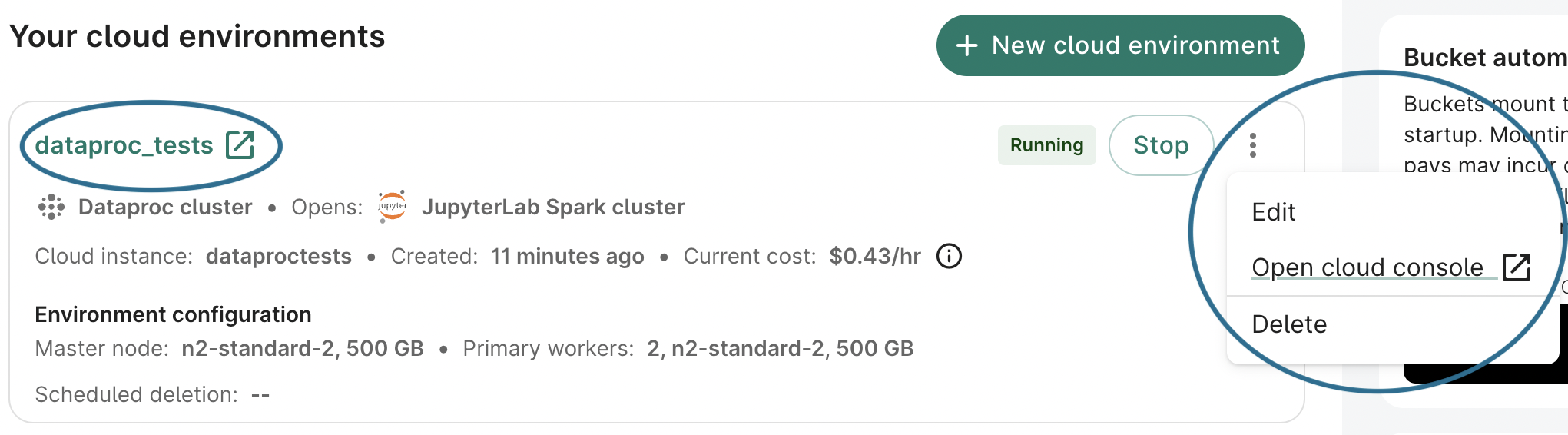
Click the cluster name (here, dataproc_tests) to open the JupyterLab
server that is running on the "main" cluster node. Click the three-dot menu to open the Dataproc dashboard in the Google Cloud
console, or to delete the cluster.
Navigating the JupyterLab file system on the "main" cluster node
As noted above, click the cluster name to open the cluster’s JupyterLab server, which is running on the "main" node of the cluster.
In the left-hand File navigator, the top-level directory maps to /home/dataproc. The
notebook user is dataproc, and if you open a
terminal window, it will be set to the /home/dataproc directory as well.
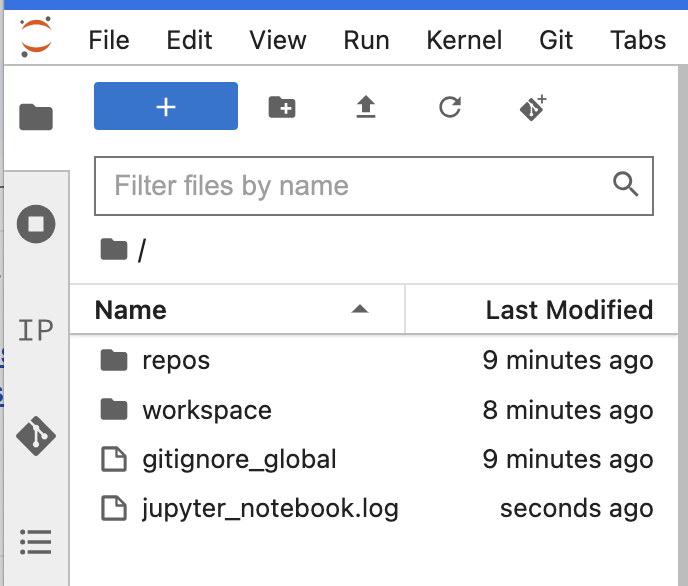
In /home/dataproc, you’ll see a repos subdirectory and a workspace subdirectory.
The repos directory holds clones of any GitHub repositories that you’ve added to your workspace, as described here.
The workspace directory holds mounted workspace buckets and referenced folder resources, as described here.
The first time a Dataproc cluster is created in a workspace, two controlled resource buckets are automatically created: a staging bucket, and a temp bucket. The files in these buckets will be automounted under /home/dataproc/workspace, along with automounts of other resources you’ve created.
Tip
If you’re familiar with an “out-of-the-box” Dataproc installation, you may be aware that files saved to{STAGING_BUCKET}/notebooks/jupyter/ are automounted to the notebook server’s file system and
changes persisted to the staging bucket. This still holds, but with Workbench, all controlled Cloud Storage resources
are automounted (including the staging bucket), and you can place your notebook files in whichever
controlled resource bucket you prefer.
Persisting notebooks across clusters
When a Dataproc cluster is deleted, its node’s disks are deleted as well.
There are multiple approaches for persisting your work across clusters:
- You can create notebook files and other artifacts in the mounted resource directories under
~/workspace. This will save your files in Cloud Storage, as discussed above and described in more detail here. Note that all users with Writer or Owner privileges for the workspace have write access to these controlled resource buckets. - You can work with
git, and check in your changes to a GitHub repo before you shut down the cluster.
These two features work the same on the Dataproc JupyterLab server as they do in a notebook app server.
Accessing the Workbench CLI from on-cluster notebooks
The Workbench CLI utility, wb, is installed on the Dataproc JupyterLab server node, and
initialized for the current workspace (similarly to how the notebook VM
servers are configured).
You can use wb from the terminal window or from a notebook cell to do things like create clusters (as described above), create
resources, resolve resource names, and more.
See the example notebooks for an example of this.
Pausing (stopping), restarting, or deleting a cluster
You can stop (pause) a running cluster, restart a stopped cluster, or delete it in the Workbench web UI.
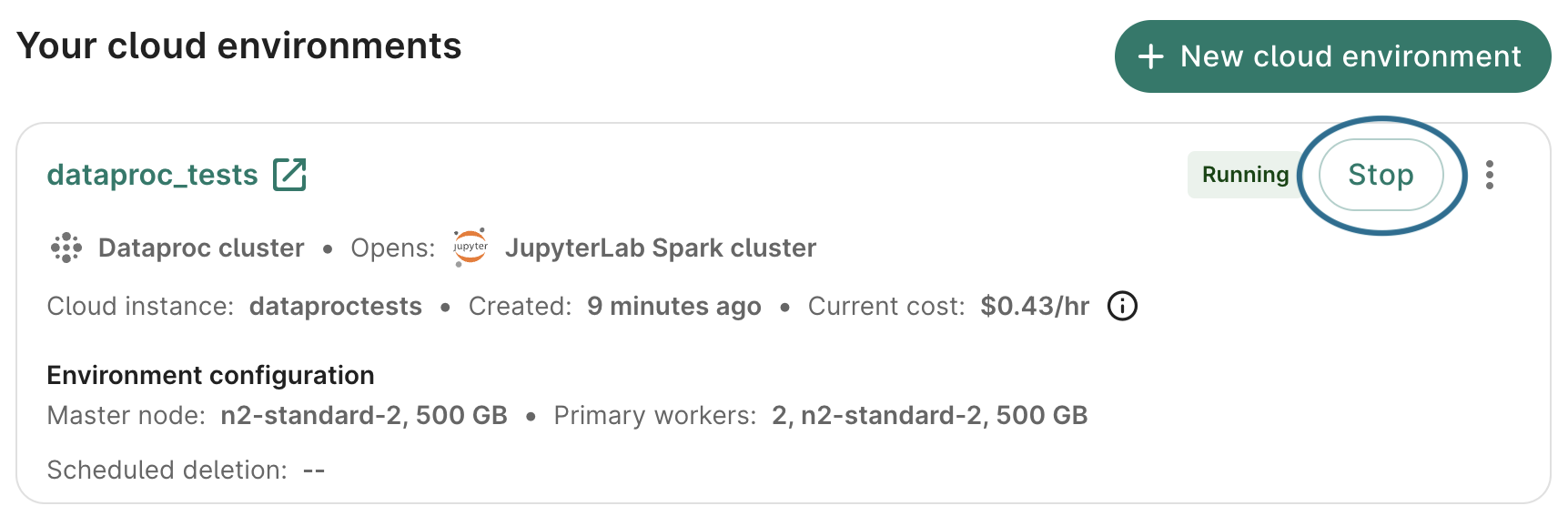
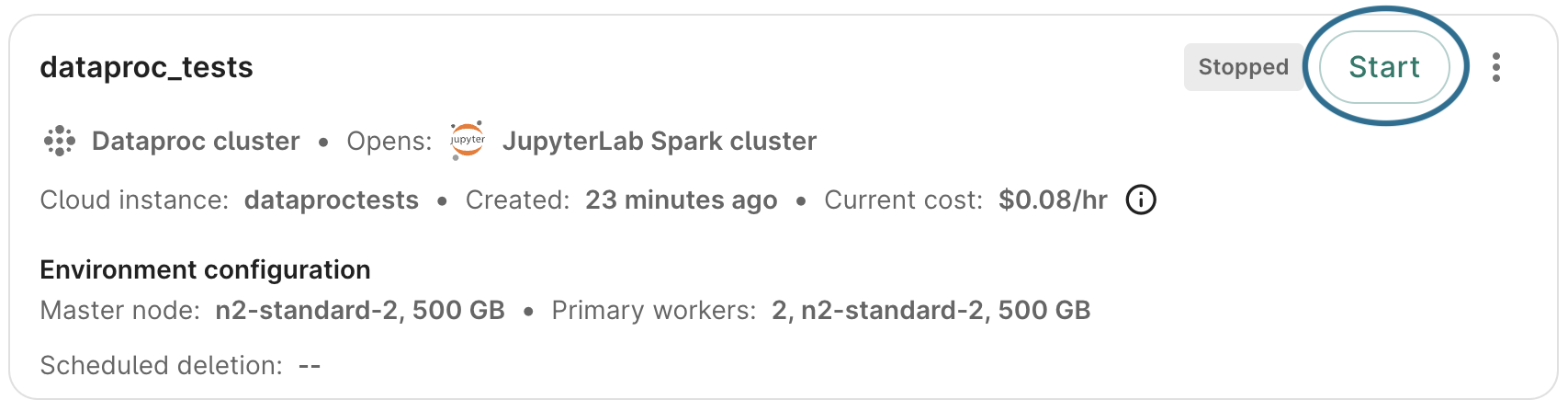
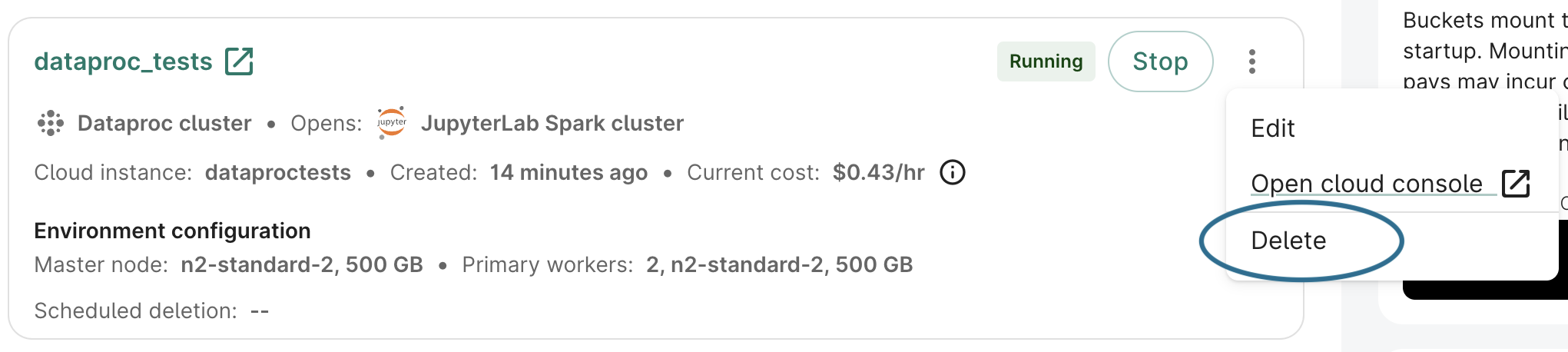
You can also stop/restart/delete a cluster from the Cloud console, as described below.
Scheduled deletion still applies to stopped clusters.
If you have any secondary workers running as part of a cluster, the cluster cannot be stopped. You will first need to edit your cluster configuration, as described in the next section, to set the secondary workers to 0 nodes. Note that if the cluster is "UPDATING" (e.g., if autoscaling is engaged to turn nodes up or down), you will need to wait until the update is finished to make edits.
Changing the configuration of an existing Dataproc cluster
You can change some aspects of a cluster's configuration after it has been created. Specifically, you can edit the cluster's app name (distinct from the cluster's name in the Cloud console), change the number of primary and secondary (spot) worker nodes, select a different autoscaling policy, and update the scheduled deletion value. Note that machine type and disk size cannot be modified after creation.
Be aware
Scheduled deletion can only be edited if it is already configured on a cluster. If you disable scheduled deletion, that action can't be reversed for that cluster.To make changes to a cluster app, click on the three-dot menu for the cluster, then select Edit.
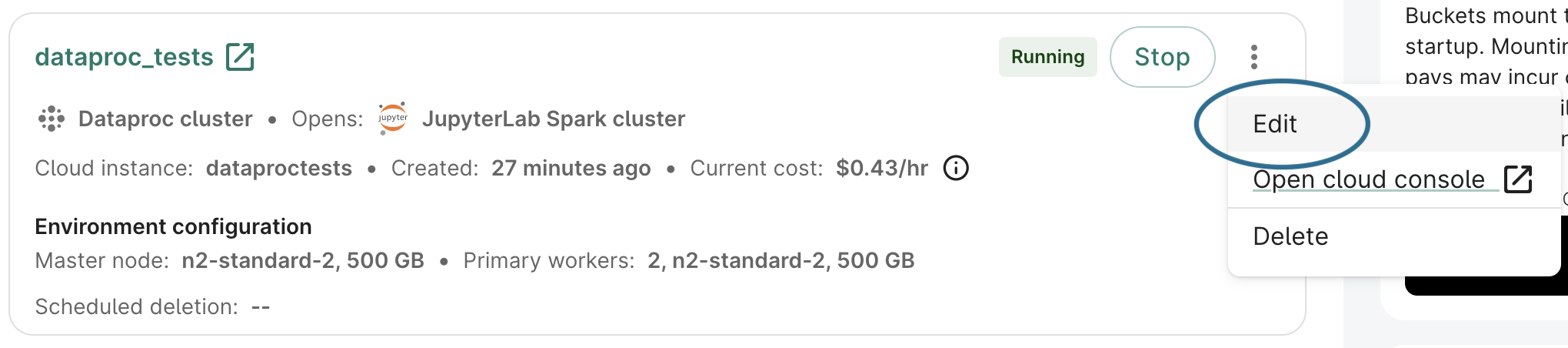
The figure below shows how to edit the number of spot workers:
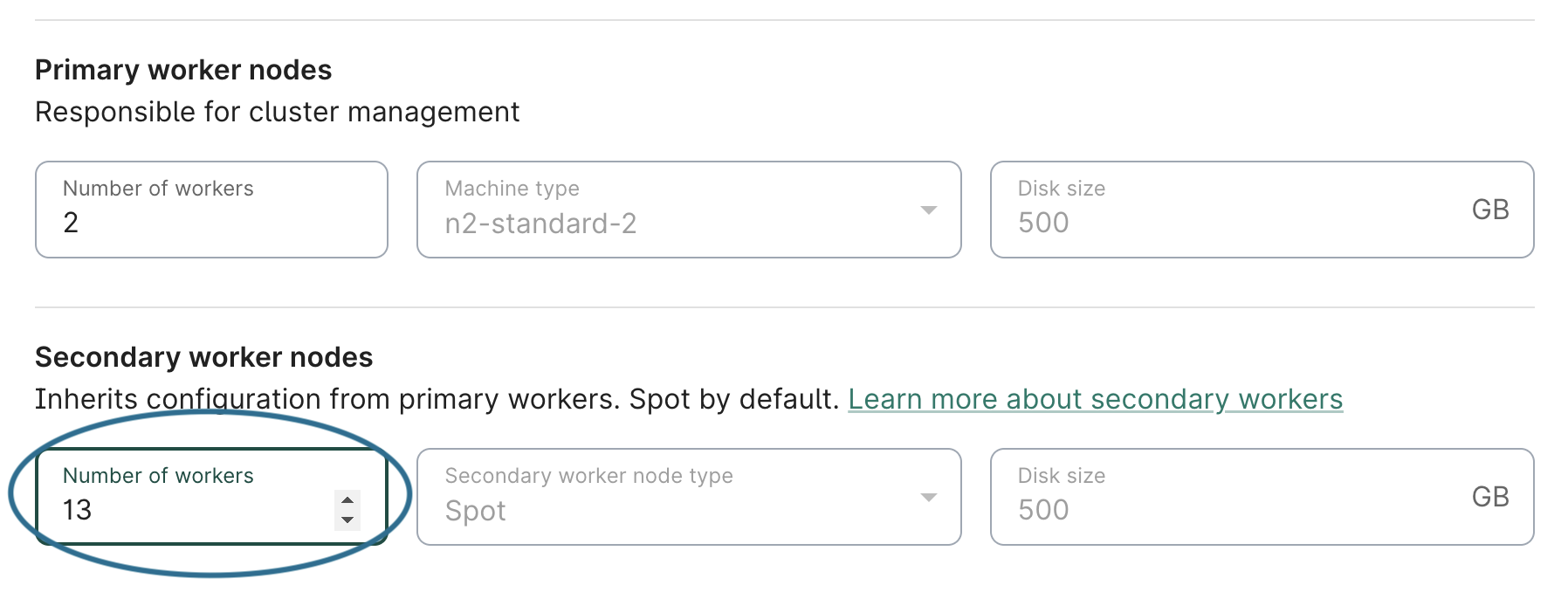
Note
The cluster needs to be in aRUNNING state to edit nearly all configuration settings. Only the cluster's app name can be edited if the cluster is in a STOPPED or UPDATING state.
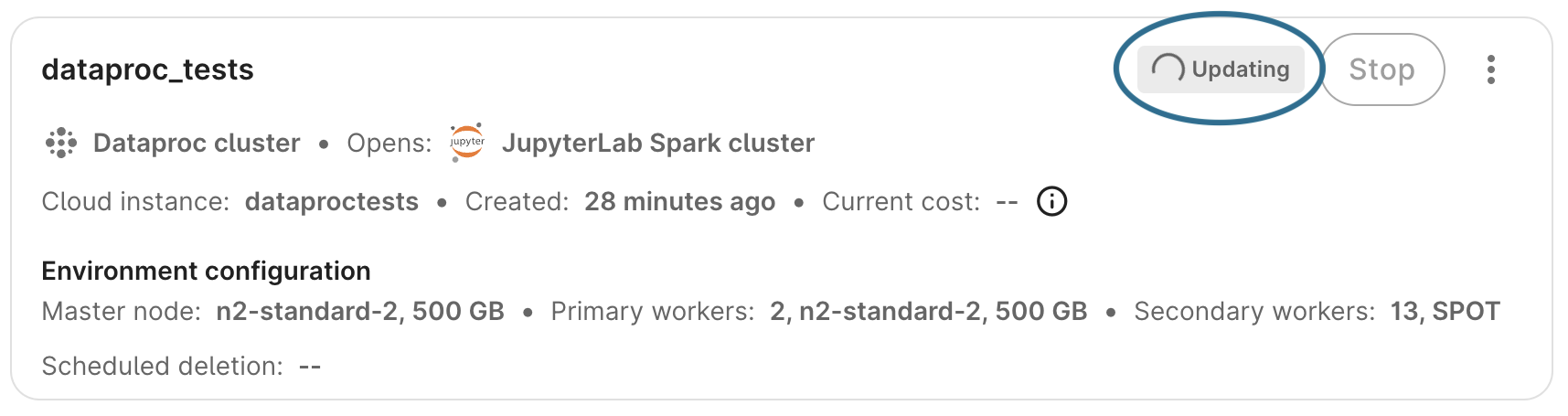
Accessing the Dataproc dashboard in the Google Cloud console
You can open the Dataproc dashboard in the Google Cloud console by clicking the Open Cloud console link under the three-dot menu for the running cluster. You can also click on the project link on your workspace’s Overview tab to open the Cloud console and navigate to the Dataproc panel.
The console’s Dataproc dashboard gives you access to a range of monitoring panels, logs, and web interfaces, and allows submission of batch jobs.
You can also stop and start a cluster via the Cloud console, and edit a cluster config to change its number of primary and secondary workers.
Note
Cluster creation must be done via the Workbench web UI or CLI, not the Cloud console.How to submit a batch job to a Dataproc cluster
You can submit a batch job using gcloud like this:
gcloud dataproc jobs submit pyspark --cluster {HAIL_CLUSTER_NAME} --region us-central1 \
<your_batch_script>.py
See this notebook file for an example.
You can run this command from a workspace notebook app (both a “regular” notebook app or the Dataproc cluster app), or from your local machine. Locally, you may need to set the
--project flag as well, if gcloud is not configured for the correct project.
You can also submit a batch job from the Dataproc dashboard in the Cloud console.
Dataproc in shared workspaces
Where a workspace is shared with multiple users, those with Writer or Owner privileges can create Dataproc clusters in the workspace. Those with Reader privileges can't create clusters, though they will be able to duplicate (clone) the workspace and create clusters in the cloned workspace.
Users cannot see the details of each other's clusters or access others’ notebook servers.
As described above, two controlled bucket resources are automatically created for you on first
creation of a Dataproc cluster. Their resource names are: dataproc-staging-<workspace-name>,
and dataproc-temp-<workspace-name>, where <workspace name> is replaced with the name of your
workspace. Those buckets are used by default for all Dataproc clusters in the workspace (unless a user selects a different bucket).
Examples
Some example notebooks are available here:
- Run Hail interactively on-cluster to annotate significant GWAS results with gnomAD.
- Submit a Hail batch job to the Dataproc cluster.
Last Modified: 11 December 2024